
목차
오라클에서 DISTINCT 키워드는 SELECT 문에서 중복된 값을 제거하고 고유한 값만을 반환하는 기능을 합니다.
GROUP BY 또한 중복된 값을 제거하는 역할을 하지만 집계함수를 이용하여 다른 컬럼에대한 값을 계산할 수 있습니다.
DISTINCT: SELECT 문에서 중복된 값을 제거하여 고유한 결과만 반환하는 데 사용됩니다. 특정 열이나 여러 열의 중복되지 않은 값들을 조회할 때 주로 사용합니다. 조회된 결과에는 고유값만 나오며 중복된 항목에 따라 행의 개수가 줄어들 수 있지만 내용은 원본 데이터입니다.
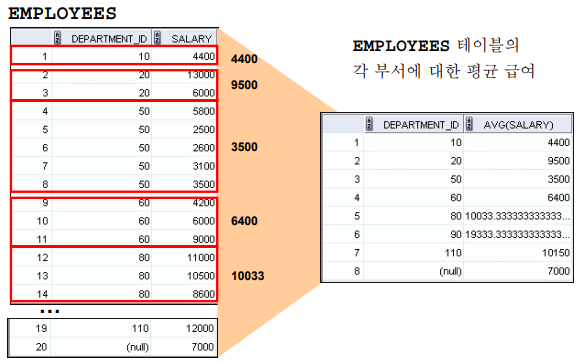
GROUP BY: 특정 열을 기준으로 행들을 그룹화하고, 그룹별로 집계 함수를 적용할 때 사용됩니다. 각 그룹에 대해 계산된 결과를 반환합니다. COUNT, SUM, AVG, MAX, MIN 등의 집계 함수와 함께 사용되는 경우가 많습니다. 집계 함수가 사용되기 때문에 DISTINCT에 비해 가공된 데이터라는 느낌입니다. SELECT 절에 GROUP BY에 포함된 컬럼이나 집계 함수와 함께 사용해야하기 때문에 초보자 분들은 까다롭게 느끼실 수 있습니다.
그러나 두 키워드에는 다음과 같은 차이점이 있습니다.
- DISTINCT는 SELECT 절에 위치하며, 하나 이상의 컬럼에 적용할 수 있습니다.
- GROUP BY는 SELECT 절의 컬럼을 GROUP BY 절에도 동일하게 명시해야 합니다.
- DISTINCT는 단순히 그룹핑 작업만 수행하고 결과를 반환합니다. GROUP BY는 그룹핑과 함께 정렬 작업도 수행합니다 (Oracle 10g R2부터는 정렬이 기본으로 되지 않습니다).
- DISTINCT는 임시 테이블스페이스에 데이터를 저장하고 작업하는 방식이므로 시스템에 부하를 줄 수 있습니다.
- GROUP BY는 DISTINCT보다 성능면에서 조금 더 우수합니다.
- DISTINCT는 집계 함수와 함께 사용할 수 없으나 GROUP BY는 집계 함수와 함께 사용할 수 있으며, HAVING 절과도 결합할 수 있습니다.
중복 제거가 목적이고 정렬이나 집계가 필요하지 않다면 DISTINCT를 사용하는 것이 간결하고 직관적입니다.
그러나 데이터가 많고 시스템 부하를 줄이고 싶거나 정렬이나 집계가 필요하다면 GROUP BY를 사용하는 것이 좋습니다.
사실 이 둘은 용도가 달라서 실제로 업무하시다보면 둘중 어떤 것을 쓸지 고민되는 경우는 거의 없었던것 같습니다.
저같은 경우는 간단히 중복이 제거된 데이터를 조회하거나 DISTINCT를 썼을 때 쿼리가 직관적인 경우 DISTINCT를 사용하고 그 외에는 GROUP BY를 사용합니다.
1. DISTINCT의 사용
1-1. 특정 열의 고유한 값 조회
employees 테이블에서 고유한 직책(title)을 조회하고 싶다면, 다음과 같이 DISTINCT 키워드를 사용할 수 있습니다.
SELECT DISTINCT title FROM employees;
이 쿼리는 테이블의 title 열에서 중복되지 않은 고유한 직책들만 반환합니다.
1-2. 여러 열의 고유한 값 조합 조회
DISTINCT 키워드는 여러 열에 대해 고유한 값 조합을 조회하는 데에도 사용할 수 있습니다.
테이블에서 고유한 직책(title)과 부서(department) 조합을 조회하려면 다음과 같이 작성할 수 있습니다.
SELECT DISTINCT title, department FROM employees;
이 쿼리는 테이블에서 title과 department 열의 중복되지 않은 고유한 조합을 반환합니다.
1-3. GROUP BY와 조합
DISTINCT 키워드는 집계 함수와 함께 사용되어, 고유한 값들에 대한 통계를 계산할 수 있습니다.
테이블에서 각 부서별로 고유한 직책(title)의 개수를 조회하려면 다음과 같이 작성할 수 있습니다.
SELECT department, COUNT(DISTINCT title) as unique_title_count
FROM employees GROUP BY department;
이 쿼리는 각 부서별로 고유한 직책의 개수를 세어 반환합니다.
2. GROUP BY의 사용
2-1. 부서별 직원 수 조회
employees 테이블에서 각 부서별로 직원 수를 조회하려면 다음과 같이 GROUP BY 절을 사용할 수 있습니다.
SELECT department, COUNT(*) as employee_count FROM employees GROUP BY department;
이 쿼리는 테이블의 department 열을 기준으로 데이터를 그룹화하고, 각 부서별로 직원 수를 세어 반환합니다.
2-2. 부서별 평균 급여 조회
employees 테이블에서 각 부서별로 평균 급여를 조회하려면 다음과 같이 작성할 수 있습니다.
SELECT department, AVG(salary) as average_salary FROM employees GROUP BY department;
이 쿼리는 각 부서별로 급여(salary)의 평균을 계산하여 반환합니다.
2-3. 여러 열을 기준으로 그룹화
GROUP BY 절에서는 여러 열을 기준으로 데이터를 그룹화할 수도 있습니다.
테이블에서 부서별, 직책별로 직원 수를 조회하려면 다음과 같이 작성할 수 있습니다.
SELECT department, title, COUNT(*) as employee_count
FROM employees GROUP BY department, title;
이 쿼리는 department와 title 열을 기준으로 데이터를 그룹화하고, 각 그룹별로 직원 수를 세어 반환합니다.
2-4. HAVING 절
GROUP BY 절과 함께 HAVING 절을 사용하여, 특정 조건을 만족하는 그룹만을 조회할 수 있습니다.
테이블에서 직원 수가 10명 이상인 부서만 조회하려면 다음과 같이 작성할 수 있습니다.
SELECT department, COUNT(*) as employee_count
FROM employees GROUP BY department HAVING employee_count >= 10;
이 쿼리는 각 부서별로 직원 수를 세고, 직원 수가 10명 이상인 부서만을 조회하여 반환합니다. HAVING 절은 GROUP BY 절 뒤에 위치하며, 그룹화된 결과에 대한 필터 역할을 수행합니다.
2-5. ORDER BY 절
GROUP BY 절과 함께 ORDER BY 절을 사용하여 그룹화된 결과를 특정 열을 기준으로 정렬할 수 있습니다. 테이블에서 부서별로 직원 수를 조회하되, 직원 수가 많은 순서대로 정렬하려면 다음과 같이 작성할 수 있습니다.
SELECT department, COUNT(*) as employee_count
FROM employees GROUP BY department ORDER BY employee_count DESC;
이 쿼리는 각 부서별로 직원 수를 세고, 직원 수가 많은 순서대로 결과를 정렬하여 반환합니다.
이처럼 GROUP BY 절은 데이터를 그룹화하고 집계 함수를 적용하여 그룹별 통계를 계산하는 데 유용하게 사용됩니다.
상황에 따라 다양한 방식으로 사용할 수 있으며, 필요한 경우 HAVING 절이나 ORDER BY 절과 같이 사용할 수 있습니다.
3. UNION을 이용한 중복 제거 방법
SELECT 문에서 UNION을 이용해서도 중복을 제거할 수 있습니다. UNION ALL은 중복된 내용도 출력해주지만 UNION은 중복된 내용은 출력하지 않는 것을 이용하여 중복을 제거하는 것입니다.
UNION에 대해 간산히 설명드리자면 두 개 이상의 SELECT 쿼리의 결과를 하나의 결과로 합치는 데 사용되는 연산자입니다.
각 SELECT 문의 열 개수와 데이터 타입이 동일해야 한다는 점만 주의하시면 사용하시는데 어려움이 없으실 겁니다.
SELECT columnA, columnB FROM table1 UNION SELECT columnA, columnB FROM table2;
이외에도 중복을 제거하는 방법은 있지만 특수한 상황에서 사용되고 가독성도 떨어지므로 이정도만 알아도 중복제거에는 문제가 없으실 것 같습니다.
'오라클' 카테고리의 다른 글
| 오라클 사용자 정의 함수 (0) | 2023.03.28 |
|---|---|
| WHERE 절에서 연산자 사용 (0) | 2023.03.26 |
| 오라클 데이터 타입과 정확히 작성해야 하는 이유 (0) | 2023.03.22 |
| sql에서 가독성을 높이는 별칭 사용법(Column Aliases, Table Aliases) (0) | 2023.03.18 |
| 10 x null = ?, null(널)에 대해 알아야할 사항 (0) | 2023.03.16 |




