
목차
지난 포스팅에서는 구글 스프레드시트를 이용하여 크롤링하는 방법을 알아봤습니다. 크롤링을 처음 하시는 분들은 XPath가 가장 어려운 부분이라고 생각되어 XPath에 대해 조금 더 알아보려 합니다. 지난 시간에 알아봤던 전체 XPath경로를 복사하는 방법도 있지만 동적으로 내용이 변한다던가 하는 경우네는 이렇게 해서 값을 가져오지 못하는 경우도 있습니다. 또한 가져온 문자열을 잘라서 보여주고 싶은 경우도 있을 것입니다. 오늘은 이러한 IMPORTXML 사용법에 대한 응용을 살짝 맛보겠습니다.

구글 스프레드시트를 이용한 기본적인 크롤링 방법이 궁금하시다면 아래 포스팅에서 네이버 주식에서 현재가를 가져오는 방법을 설명한 포스팅이 있으니 참고해주시기 바랍니다.
프로그램 한 줄 없이 크롤링 하는 방법(ft. 구글 스프레드시트)
구글의 엑셀, 스프레드시트에서 크롤링이 가능하고 IMPORTXML함수를 사용하여 크롤링을 합니다. 크롤링을 하려면 파이썬이니 뭐니 배워서 하는 게 아닌 엑셀의 함수 하나만 가지고도 가능한 것입
dolpali.tistory.com
1. Absolute XPath의 한계
이전 포스팅에서 사용했던 개발자 도구를 이용하여 XPath를 가져오는 것은 Absolute XPath라고 합니다. 한마디로 절대 경로라고 할 수 있는데 root부터 해당 위치까지 어떻게 찾아갈 수 있는지를 하나하나 적은 것이라고 볼 수 있습니다.

이런 경우에 기존 XPath에서 element가 하나 추가되거나 삭제되기만 해도 경로가 맞지 않는다는 점이 단점이지만 개발자 도구에서 쉽게 XPath를 가져올 수 있기 때문에 처음에 시도해 볼만합니다. 하지만 페이지가 동적으로 만들어지는 사이트에서는 Absoute XPath로는 제대로 된 값을 가져오기가 힘듭니다. 이런 경우 Relative XPath를 사용하여 해결할 수도 있습니다. 또한 Relative XPath를 적절히 사용하면 XPath의 전체 길이도 짧아지고 가독성도 높아집니다. Relative XPath에서 사용하는 표현식은 다음과 같은 것들이 있습니다. 이러한 표현식을 사용하여 크롤링하는 방법을 알아보겠습니다.
//:현재 위치의 모든 자식 노드에서 검색
*:경로에 있는 모든 노드 반환
[]:필터 표현식
[@attr]:해당 속성을 가지고 있는 모든 노드를 반환
[@attr="value"]: attr의 속성중에 value와 일치하는 노드를 모두 반환
2. XPath의 응용

이전 포스팅인 "프로그램 한 줄 없이 크롤링하는 방법"을 보셨다면 사람인에서 넥슨 채용글의 조회수를 가져올 때 아래와 같이 url과 XPath를 입력해야 한다는 것을 알 수 있습니다.
=IMPORTXML("https://www.saramin.co.kr/zf_user/jobs/relay/pop-view?rec_idx=47219711&t_ref=main&t_ref_content=eutteum_fix",
"/html/body/section/div/div/div[3]/section/div[1]/div[2]/div/div[3]/ul/li[1]/strong")
이러한 Absolute XPath를 바꾸기 위해서 위에서 설명드렸던 표현식을 이용할 수 있습니다.

개발자 도구에서 조회수 부분의 html을 확인하고 해당 부분을 표현식으로 변경해 줍니다.
=IMPORTXML("https://www.saramin.co.kr/zf_user/jobs/relay/pop-view?rec_idx=47219711&t_ref=main&t_ref_content=eutteum_fix","//ul[@class='list_meta']/li")
//를 이용하여 문서의 루트에서 시작하고 개발자에서 본 elemet를 순서대로 적어줍니다. ul[@class='list_meta']은 ul요소 중에 class 속성이 list_meta인 것의 내용을 크롤링해오라는 뜻이고 그 뒤에 li은 그중 li요소를 다 가져오라는 뜻입니다.

여기까지 하셨다면 값을 가져오긴 하지만 근처에 있는 다른 정보도 함께 가져오는 것을 볼 수 있습니다. 원하는 값인 조회수만 가져오기 위해 표현식을 조금 더 다듬어 주겠습니다. 조회수, 홈페이지접속, 공유하기 등은 각각 모두 li 태그 안에 있습니다.

이러한 li 태그 중에 어떤 것을 가져올지 지정하지 않아서 모든 것을 가져오게 됩니다. 위 그림을 보시면 [1]에 조회수, [2]에 홈페이지접속, [3]에 공유하기, [4]에 신고하기가 있습니다. 이런 식으로 데이터가 모여 있는 것을 배열이라고 하는데 [] 안에 있는 숫자는 배열에서 각 데이터의 주소라고 생각하시면 되겠습니다. 우리는 조회수를 가져올 예정이니 li에서 첫 번째 데이터를 가져오도록 표현식을 변경해 줍니다.
=IMPORTXML("https://www.saramin.co.kr/zf_user/jobs/relay/pop-view?rec_idx=47219711&t_ref=main&t_ref_content=eutteum_fix","//ul[@class='list_meta']/li[1]")
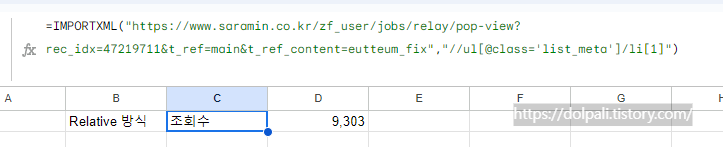
수식을 변경했더니 원하던 대로 조회수만 가져옵니다. 하지만 조회수라는 글자는 필요 없고 숫자만 필요하므로 마지막으로 수식을 변경해 주겠습니다.

html을 보니 숫자 부분은 strong태그로 감싸져 있습니다. strong만 가져온다면 모든 문제가 해결될 것 같습니다.

=IMPORTXML("https://www.saramin.co.kr/zf_user/jobs/relay/pop-view?rec_idx=47219711&t_ref=main&t_ref_content=eutteum_fix","//ul[@class='list_meta']/li[1]/strong")
마지막에 strong태그만 가져오도록 표현식을 변경하여 원하는 조회수만 나오도록 했습니다. 처음에는 어려워 보이실 수 있지만 한 두 번 하다 보면 요령이 생기실 것입니다. 그리고 한 가지 주의사항은 한 화면에서 여러 개의 데이터를 가져와야 하는 경우 건건이 가져오는 것보다 한 화면 전체를 읽어와서 데이터를 잘라주는 것(파싱)이 좋습니다. 왜냐하면 너무 자주 페이지를 호출하는 경우 해당사이트에 무리가 갈 수 있고 스프레드시트에서도 과한 로드가 걸리게 되어 느려지게 되기 때문입니다.
'IT issue' 카테고리의 다른 글
| 마이크로소프트 Bing 채팅, Bing 코파일럿 사용할 수 없을 때 해결 방법 (0) | 2024.02.19 |
|---|---|
| 브라우저 별 실수 닫힌 창 복구하기(ft. 크롬, 엣지) (0) | 2024.01.09 |
| 프로그램 한 줄 없이 크롤링 하는 방법(ft. 구글 스프레드시트) (2) | 2023.12.29 |
| 갤럭시 스마트폰에서 폰트(글꼴)를 어떻게 변경 할 수 있을까? (0) | 2023.11.11 |
| 마이크로소프트 광고는 애드센스를 대신할 수 있을까? (0) | 2023.11.04 |



