
목차
구글의 엑셀, 스프레드시트에서 크롤링이 가능하고 IMPORTXML함수를 사용하여 크롤링을 합니다. 크롤링을 하려면 파이썬이니 뭐니 배워서 하는 게 아닌 엑셀의 함수 하나만 가지고도 가능한 것입니다. 기존에 엑셀에도 크롤링하는 기능이 있지만 IE기반이어서 IE를 지원하지 않는 사이트에서는 크롤링이 되지 않는 문제가 있습니다.(2019 기준) 대부분의 기능은 MS 엑셀이 스프레드시트보다 낫다고 생각하지만 크롤링만큼은 현 시전에 구글의 스프레드시트가 조금 더 낫지 않나 싶습니다. 네이버 주식에서 주식정보를 가져오는 방법을 알아보겠습니다.

글을 쓰려고 찾다보니 주식을 하시는 분들이 크롤링을 많이 이용하시는 것을 알 수 있었고 조금만 응용하시면 코인에서도 사용가능할 것 같습니다. 물론 프로그램을 할 줄 아신다면 공식 API를 이용하여 데이터를 가져오는 것이 더 좋습니다만, 이번 포스팅은 크롤링은 하고 싶은데 프로그램은 할 줄 모르는 분이 대상이기 때문에 API를 이용한 방법은 제외하겠습니다.
구글의 스프레드시트 사용법은 아래 포스팅을 참고해 주시기 바랍니다.
무료 엑셀을 사용하기 Ver.2(ft. 구글 스프레드시트)
이전 포스팅에서 무료로 사용할 수 있는 엑셀로 오피스 365를 추천해 드렸습니다. 이번에는 협업에 조금 더 용이한 구글 스프레드시트의 사용법과 협업 방법을 알아보겠습니다. 물론 오피스 365
dolpali.tistory.com
1. IMPORTXML 사용법
IMPORTXML(url, xpath_query, locale)
url: 크롤링하고 싶은 페이지를 뜻합니다.
xpath_query: 크롤링하고 싶은 페이지에서 가져오고 싶은 항목을 정확히 지정해 주는 쿼리입니다.
locale: 데이터를 가져와서 파싱 할 때 사용할 언어입니다.
위 세가지만 입력해 주면 크롤링해 올 수 있습니다. 크롤링에서 가장 어려운 부분이라고 하면 xpath_query일 것입니다. 브라우저에서 xpath를 지원해주고 있지만 동적인 페이지나 일부 페이지에서는 xpath가 제대로 동작하지 않을 수 있기 때문에 여러 가지 방법을 시도해야 할 수도 있습니다. 이러한 과정은 어떤 방법, 예를 들어 많이 하는 파이썬을 이용해도 마잔가지이기 때문에 한 번은 겪어야 할 어려움입니다. 하지만 이 부분만 잘 해결하면 원하는 데이터를 가져올 수 있을 것입니다.
2. 네이버 증권에서 주식정보 크롤링 하기
2-1. 삼성전자 현재가 가져오기

네이버 증권에서 위 그림과 같은 페이지에서 현재가를 가져오는 부분을 설명 드리겠습니다.
https://finance.naver.com/item/sise.naver?code=005930
위 주소에 접속하면 현재가, 등락률, 거래량, 매도, 매수 호가 등 삼성전자 주식에 대한 다양한 정보를 가져올 수 있습니다.
해당 주소에 접속 한 후 F12를 눌러줍니다. 개발자 도구라고 하는데 크롤링을 하기 위해서는 알아두셔야 합니다.
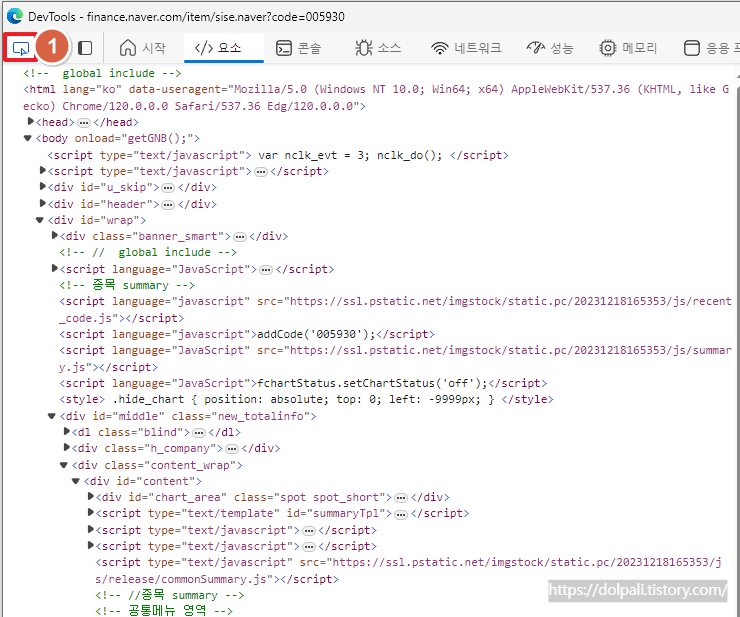
1. (F12를 눌러 개발자 도구를 연 다음) 요소선택 버튼을 클릭합니다.(Ctrl+Shift+C)
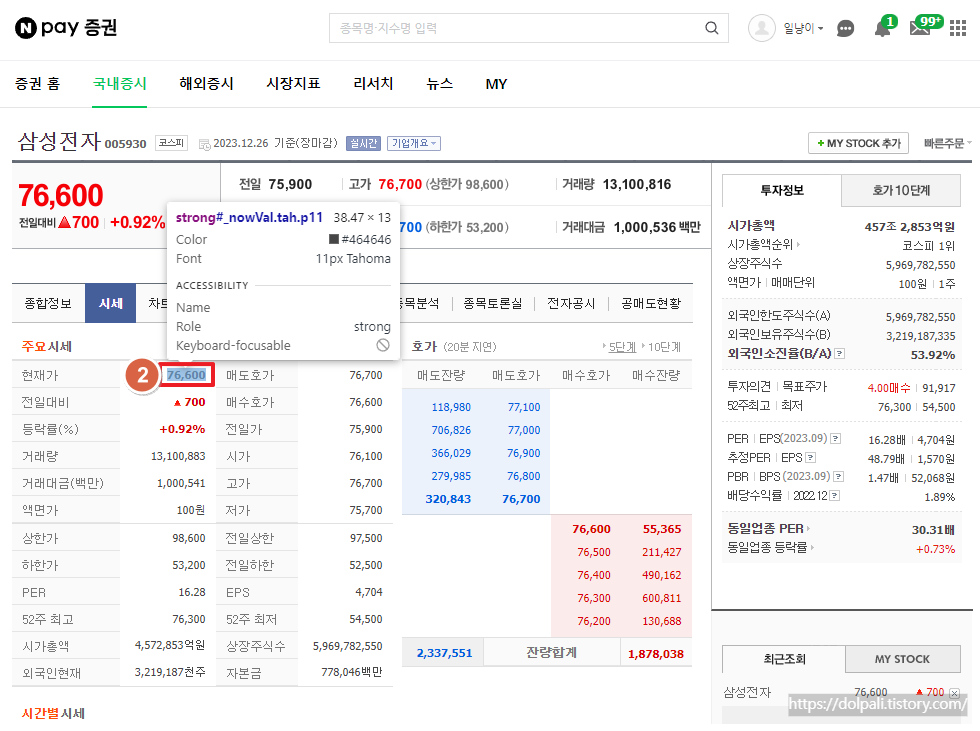
2. 웹 페이지에서 크롤링하고 싶은 숫자를 클릭합니다.
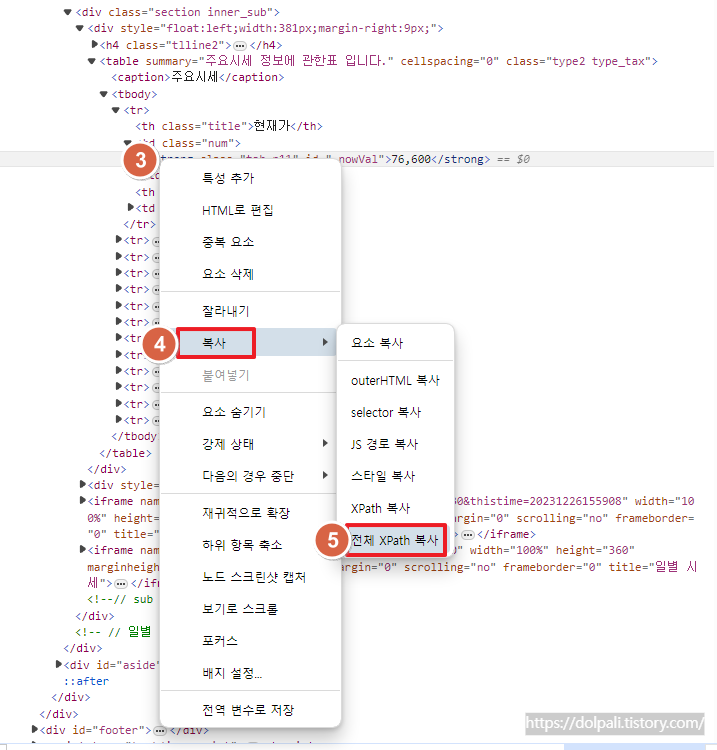
3. 개발자 도구에서 해당 숫자가 있는 html이 보일 텐데 거기서 우클릭합니다.
4. [복사]에 커서를 가져갑니다.
5. [전체 XPath 복사]를 클릭합니다.
XPath가 어떤 숫자를 가져올지 알려주는 경로라고 생각하시면 됩니다. 이제 IMPORTXML에 대입하기만 하면 됩니다.
=IMPORTXML("https://finance.naver.com/item/sise.naver?code=005930",
"/html/body/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/table/tbody/tr[1]/td[1]/strong")
위 코드를 구글 스프레드 시트에 넣으면 아래와 같이 현재가를 가져오게 됩니다.

엑셀로 주식 데이터를 만드는 경우 여러 회사의 주가를 가져오게 될 텐데 그런 경우 어떻게 하는지도 알아보겠습니다.
2-2. 다른 셀의 코드를 참조하여 현재가 가져오기
네이버에서 현재가를 가져올 때 IMPORTXML의 첫 번째 인자인 url을 보면 code를 넘겨주는 것을 볼 수 있습니다.
https://finance.naver.com/item/sise.naver?code=005930
해당 코드는 주식의 종목을 나타내는 것으로 화면 구성은 모두 똑같고 코드에 따른 가격만 달라지는 것이므로 해당 부분만 바꿔 준다면 다른 종목의 현재가도 쉽게 가져올 수 있습니다.
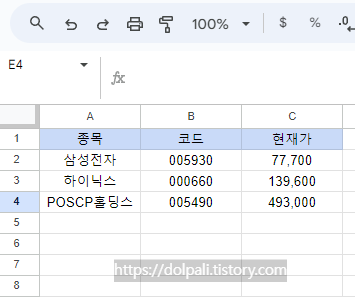
위 그림과 같이 3개 종목의 현재가를 가져와서 관리한다고 해보겠습니다.
=IMPORTXML(CONCATENATE("https://finance.naver.com/item/sise.naver?code=",B2),"/html/body/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/table/tbody/tr[1]/td[1]/strong")
XPath 부분은 똑같지만 url부분의 code를 B열에서 가져오도록 변경했습니다. CONCATENATE 함수는 두 문자열을 합쳐주는 함수라고 생각하시면 됩니다.
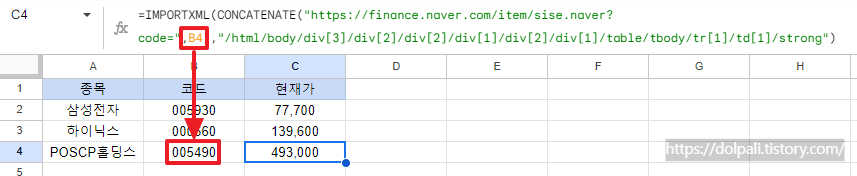
이렇게 작성하시면 code 부분이 변경될 때 함수를 수정하지 않고 B열 부분만 수정해 주면 되므로 더 편리해집니다.
다음 포스팅에서는 XPath를 복사했는데도 잘 안될 경우에 시도해 볼 수 있는 다른 방법을 소개하겠습니다.
스프레드 시트 웹 크롤링의 핵심, XPath 찾기
지난 포스팅에서는 구글 스프레드시트를 이용하여 크롤링하는 방법을 알아봤습니다. 크롤링을 처음 하시는 분들은 XPath가 가장 어려운 부분이라고 생각되어 XPath에 대해 조금 더 알아보려 합니
dolpali.tistory.com
'IT issue' 카테고리의 다른 글
| 브라우저 별 실수 닫힌 창 복구하기(ft. 크롬, 엣지) (0) | 2024.01.09 |
|---|---|
| 스프레드 시트 웹 크롤링의 핵심, XPath 찾기 (0) | 2024.01.01 |
| 갤럭시 스마트폰에서 폰트(글꼴)를 어떻게 변경 할 수 있을까? (0) | 2023.11.11 |
| 마이크로소프트 광고는 애드센스를 대신할 수 있을까? (0) | 2023.11.04 |
| 사진에서 지나가는 사람 지우기(ft. 갤럭시 AI 지우개) (0) | 2023.09.16 |



